背景
随着科技的发展,越来越多种类的智能语音产品出现。虽然智能语音产品种类,但是他们依赖着有着像汽车发动机一样重要的内核——语音对话系统(Spoken dialogue systems)。一个好的语音对话系统可以帮助用户高效的解决一些问题,或是可以和用户进行社交对话交流。下面这张图展示了语音对话系统的一般结构:
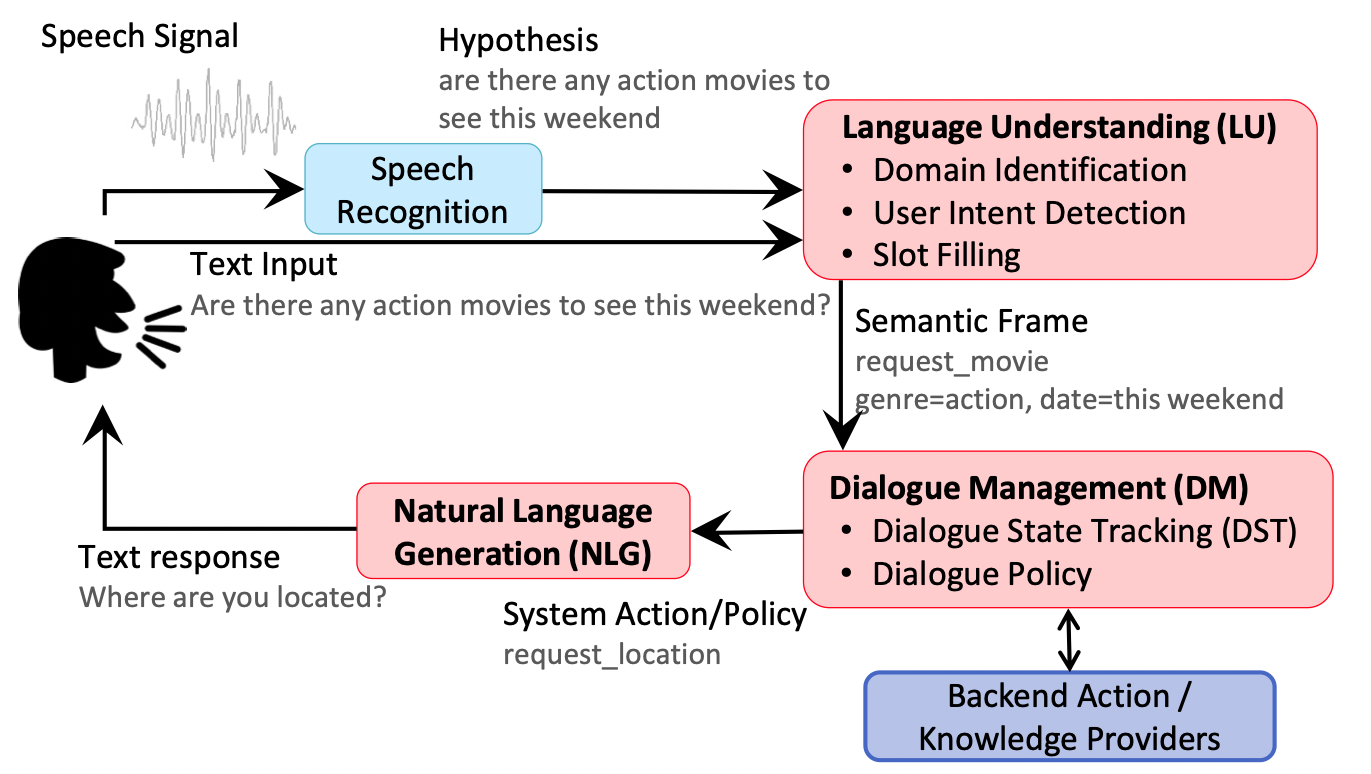
在一般的语音对话系统中都会有一个唤醒功能来启动系统,如APPLE产品中的“Hi,Siri”。系统在唤醒后会开启Voice Activity Detection ( VAD ) 状态来检测当前有没有说话声音,如果有声音则会将语音记录下来传递到ASR模块。通过ASR模块将语音转文本后,这些信息讯号会依次经过三个不同的模块(红色)处理才会反馈回人类。这三个不同的模块大致的任务可以理解为——理解信息,规划反馈,生成反馈。在语音对话系统中,第一步首先要保证输入信息的准确性,这项任务相对于上面三个模块处于上游。因为在语音交互中,由于ASR等技术的缺陷,很容易出现记录噪声或者识别错误等情况,这会影响下游任务的准确性。 基于以上原因,准确的输入信息是保证下游任务质量的基础。
在语音对话系统的信息输入中除了声音输入,还有使用文本输入的情况。中文文本纠错任务,常见错误类型包括:
- 谐音字词,如 配副眼睛-配副眼镜
- 混淆音字词,如 流浪织女-牛郎织女
- 字词顺序颠倒,如 伍迪艾伦-艾伦伍迪
- 字词补全,如 爱有天意-假如爱有天意
- 形似字错误,如 高梁-高粱
- 中文拼音全拼,如 xingfu-幸福
- 中文拼音缩写,如 sz-深圳
- 语法错误,如 想象难以-难以想象
在识别这两种信息的错误时,其方法也是不一样的的。虽然一般的语音对话系统在处理声音信息时,也是将声音讯号通过ASR技术转为文本内容,但是这种经过转换的文本内容和普通的文本内容在纠错时面临的问题是不同的,一种是根据发音的相似性纠错,另一种是根据字形的相似性纠错,所以这两种信息出错的数据分布也是不同的。此外,由于声音的约束性,一般来说普通文本信息的错误范围会比声音转换的文本信息更广。不过,在本篇文章中主要探讨针对于ASR识别后的文本数据纠错模型。
解决方法
基于规则的解决思路
- 中文纠错分为两步走,第一步是错误检测,第二步是错误纠正;
- 错误检测部分先通过中文分词器切词,由于句子中含有错别字,所以切词结果往往会有切分错误的情况,这样从字粒度(语言模型困惑度(ppl)检测某字的似然概率值低于句子文本平均值,则判定该字是疑似错别字的概率大)和词粒度(切词后不在词典中的词是疑似错词的概率大)两方面检测错误, 整合这两种粒度的疑似错误结果,形成疑似错误位置候选集;
- 错误纠正部分,是遍历所有的疑似错误位置,并使用音似、形似词典替换错误位置的词,然后通过语言模型计算句子困惑度,对所有候选集结果比较并排序,得到最优纠正词。
基于深度学习的解决思路
- 端到端的深度模型可以避免人工提取特征,减少人工工作量,RNN序列模型对文本任务拟合能力强,rnn_attention在英文文本纠错比赛中取得第一名成绩,证明应用效果不错;
- CRF会计算全局最优输出节点的条件概率,对句子中特定错误类型的检测,会根据整句话判定该错误,阿里参赛2016中文语法纠错任务并取得第一名,证明应用效果不错;
- seq2seq模型是使用encoder-decoder结构解决序列转换问题,目前在序列转换任务中(如机器翻译、对话生成、文本摘要、图像描述)使用最广泛、效果最好的模型之一。
评估方法
在纠错领域,准确率的重要性往往比召回率重要的多,所以一般使用F0.5-Score作为评估标准。在科大讯飞的纠错比赛中使用了一种综合的评估方法:。
模型
统计语言模型
错误检测
- 混淆词典匹配:混淆词典(人工添加)支持纠错和错误改正,如高梁->高粱
- 常用词典匹配:切词后不在常用词典中的词直接放入混淆集
- Ngram语言模型:某个字前后搭配的2gram和3gram的似然概率值低于句子文本的平均ppl值放入混淆集
候选召回
可根据任务的不同对混淆集进行音似或形似替换
候选排序
基于统计语言模型计算对所有替换过的句子的似然概率,取概率最大的那一个
ConvSeq2Seq
Paper: 微软亚洲研究院发表的”Reaching human-level performance in automatic grammatical error correction: An empirical study“中使用了ConvSqe2Sqe,从而首次在英文语法纠错上超过人类水平。
这篇文章的最大贡献就是提出了Fluency boost learning和Boost inference。因为在过往seq2seq的模型纠错时往往会出现两种问题,一是模型容易受训练数据的影响,对训练数据中没有见过的语法错误,改正能力很差。其二是模型很难一次修复多个错误。Fluency boost learning通过在训练过程中对数据进行增强(如下图),可以让模型看到更多的错误,增强模型的泛化能力。
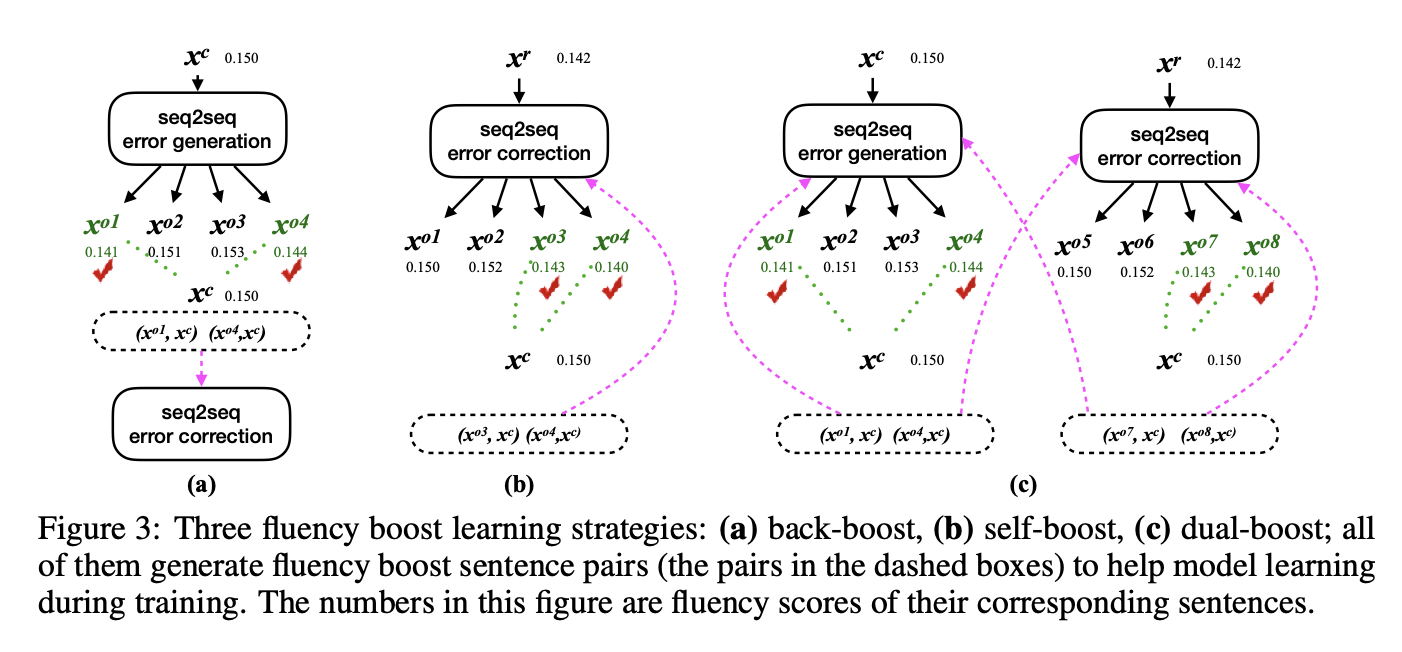
Boost inference即预测过程中进行增强,,一是多轮预测,二是循环预测。循环预测即从左到右预测和从右到左预测,比如右向左可以有效解决冠词出错问题,左向右可以解决主谓一致出错问题。
Bert模型
简介
BERT模型的工作原理是,在大型语料库(Masked LM任务)上训练BERT模型,然后通过在最后添加一些额外的层来微调我们自己的任务的模型,该模型可以是分类,问题回答或NER等。Bert是通过使用Transformer-Encoder结构,成为了一个较好的的预训练语言表示模型。Bert有两种训练任务,一种是Masked Language Model ( MLM ),另一种是Next Sentence Prediction ( NSP )。通过把Bert模型来当作任务的预训练模型,可以对提取词向量的语义特征,从而提高下有任务的表现。
结构
Bert模型中与AS纠错任务相关的是MLM部分(如下图所示), MLM训练阶段有 15% 的token被随机替换为 【MASK】 ( 占位符 ),模型需要学会根据 【MASK】 上下文预测这些被替换的token。
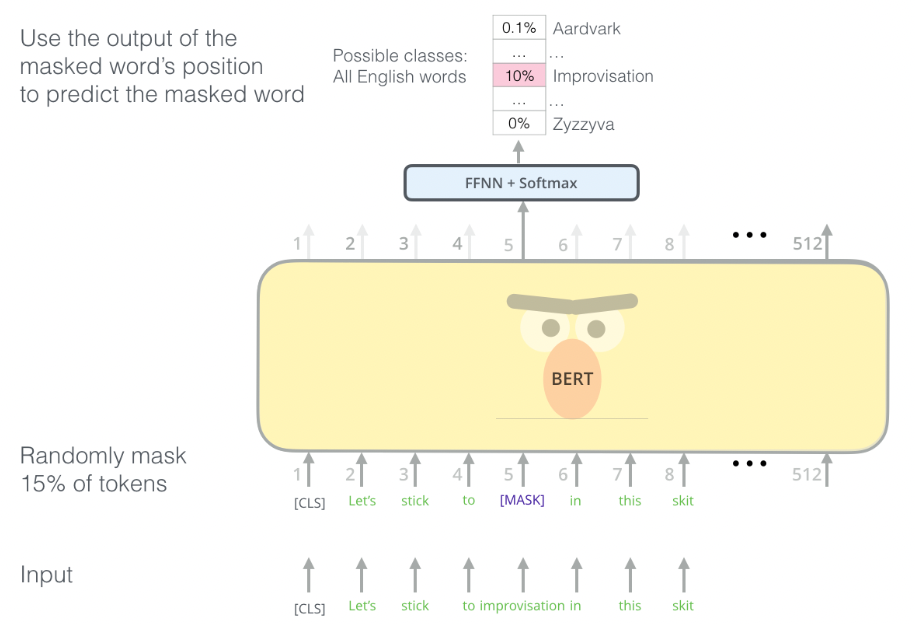
因为在实际训练中任务中没有MASK的情况,如果只利用MASK机制训练无法让模型得到好的迁移,所以模型需要对MASK的方式进行优化。
- 10% 的【MASK】会被随机替换成另一个词
- 10% 的【MASK】会被还原为正确的词
- 80% 的【MASK】保留这个占位符状态
限制
- 此外,由于BERT模型过于庞大,在一些实时要求很高的项目上很难满足时间响应范围的要求,从而导致无法上线。因此需要对BERT进行压缩处理。
- 原始的MLM的训练效率是比较低的,因为每次只能mask掉一小部分的token来训练,所以没有足够的能力来检测每个位置是否存在误差(只有15%的错误被找出),所以这种方法的精度不够好。BERT的MASK位置是随机选择的,所以并不擅长侦测句子中出现错误的位置;并且BERT纠错未考虑约束条件,导致准确率低,比如:”今 [明] 天天气怎么样”,MASK的位置是”今”, 那么纠错任务需要给出的结果是”今”。但是由于训练预料中大多数人的query都是”明天天气怎么样”,这样在没有约束的条件下,大概率给出的纠正结果是”明”,虽然句子结构是合理的,但结果显然是不正确的。
Soft-Masked BERT纠错模型
简介
Paper:Spelling Error Correction with Soft-Masked BERT
Soft-Masked BERT是字节AI-Lab与复旦大学合作提出了一种中文文本纠错模型。“Soft-Masked BERT”发表在了ACL 2020上。论文首次提出了Soft-Masked BERT模型,主要创新点在于:
- 将文本纠错划分为检测网络(Detection)和纠正网络(Correction)两部分,纠正网络的输入来自于检测网络输出。
- 以检测网络的输出作为权重,将 masking-embedding以“soft方式”添加到各个字符特征上,即“Soft-Masked”。
结构
具体来看,模型Input是字粒度的word-embedding,可以使用BERT-Embedding层的输出或者word2vec。检测网络由Bi-GRU组成,充分学习输入的上下文信息,输出是每个位置 i 可能为错别字的概率 p(i),值越大表示该位置出错的可能性越大。结构图如下:
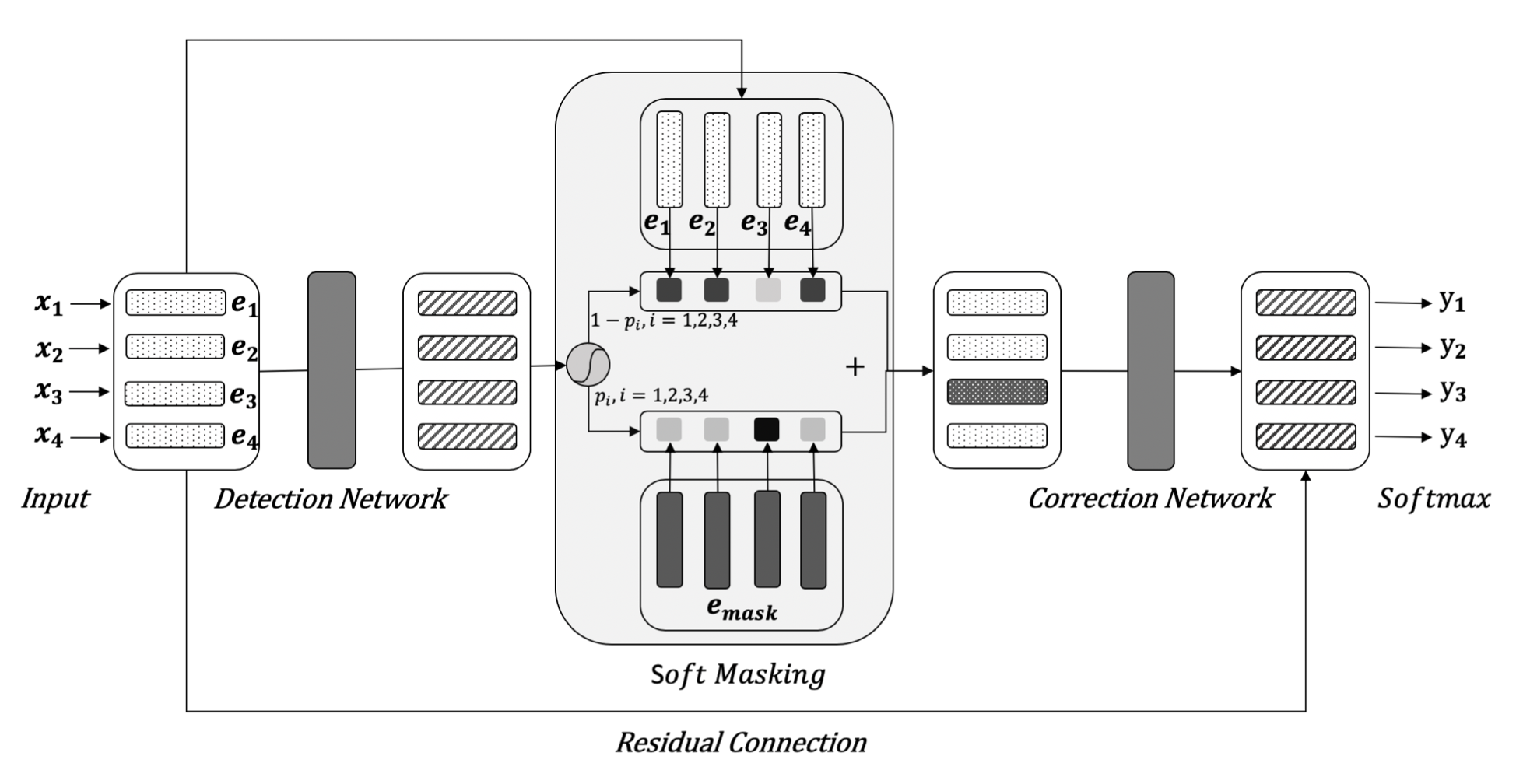
检测网络与Soft Masking
Soft Masking 部分,将每个位置的特征以 $ pi $ 的概率乘上masking 字符的特征 $emark$,以 $1-pi$ 的概率乘上原始的输入特征,最后两部分相加作为每一个字符的特征,输入到纠正网络中。
纠正网络
纠正网络部分,是一个基于BERT的序列多分类标记模型。检测网络输出的特征作为BERT 12层Transformer模块的输入,最后一层的输出 + Input部分的Embedding特征 $ei$ (残差连接)作为每个字符最终的特征表示。最后,将每个字特征过一层 Softmax 分类器,从候选词表中输出概率最大的字符认为是每个位置的正确字符。
ELECTRA模型
简介
ELECTRA的全称是Efficiently Learning an Encoder that Classifies Token Replacements Accurately。ELECTRA通过类似GAN的结构和新的预训练任务,在更少的参数量和数据下超过了BERT,而且仅用1/4的算力就达到了当时SOTA模型RoBERTa的效果。
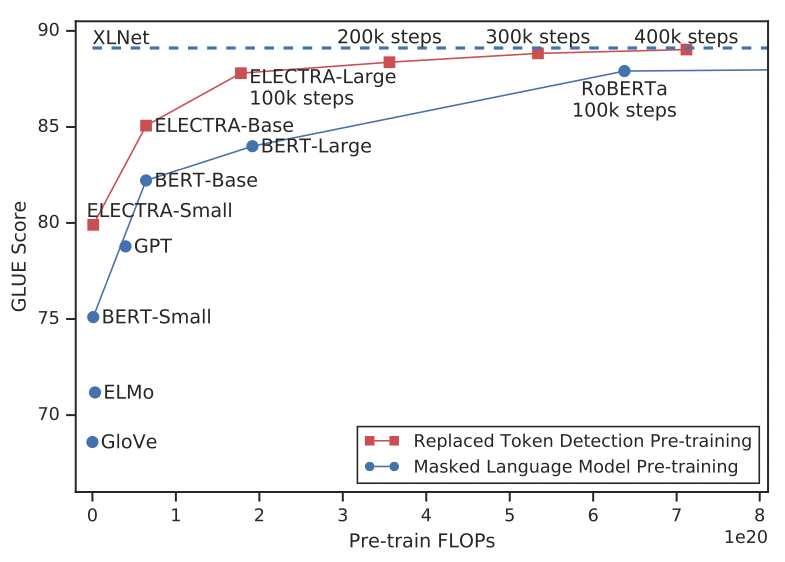
结构
ELECTRA最主要的贡献是提出了新的预训练任务和框架,把生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过。虽然BERT模型中也可以处理RTD任务,但是在随机替换一些词后,BERT在替换预测的效果并不好,因为随机替换过于简单了。ELECTRA使用一个MLM的G-BERT来对输入句子进行更改,然后丢给D-BERT去判断哪个字被改过,如下图所示:
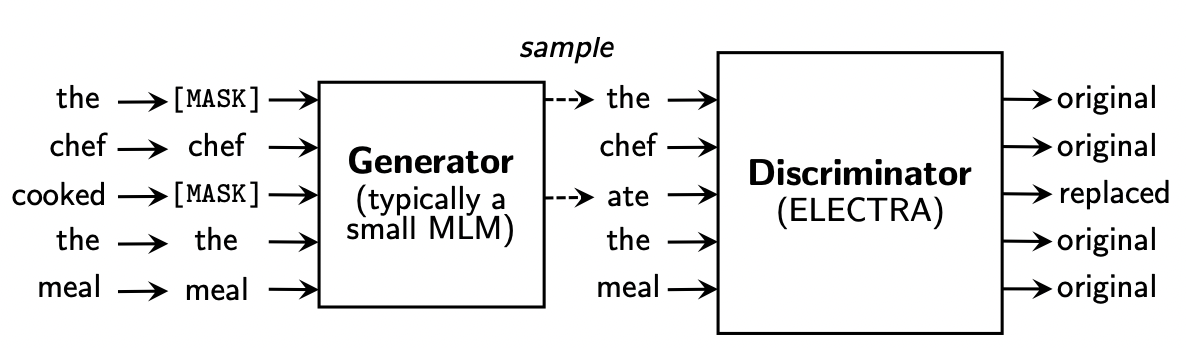
- 生成器(Generator)的作用是输入一个正确的句子,负责生成一个错误的版本,如”the chef cooked the meal”经过生成器内部随机抽样15%的token进行MASK后,再对这些MASK的位置进行预测,输出结果为”the chef ate the meal”,生成器中语言模型保证了生成的错误句子仍然是比较合理的,只是区别于原始句子。
- 判别器 ( ELECTRA ) 是用来判别生成器输出的句子中哪些位置的token被改动了,因此对每个token的位置进行original/replaced标注,如”cooked”变成了”ate”,标注为”repalced”,其余位置相同token标注为”original”,类似于序列标注任务,判别器的输出为0或1。
虽然模型的结构类似于GAN,但由于GAN应用于文本的困难,所以改模型以最大似然而不是逆向的方式训练生成器。在预训练之后,需要去掉生成器,只针对对下游任务中的鉴别器(ELECTRA模型)进行微调。
ELECTRA模型的判别器虽然可以检测错误,但模型设计不是为了纠错,而是为了在有限计算资源的条件下能提取更好特征表示,进而得到更好的效果,文章中表示在GLUE数据集上表现明显优于BERT。ELECTRA的一个变体ELECTRA-MLM模型,不再输出0和1,而是预测每个MASK位置正确token的概率。如果词表大小是10000个,那么每个位置的输出就是对应的一个10000维的向量分布,概率最大的是正确token的结果,这样就从原生ELECTRA检测错误变成具有纠错功能的模型。
工具
pycorrector
pycorrector依据语言模型检测错别字位置,通过拼音音似特征、笔画五笔编辑距离特征及语言模型困惑度特征纠正错别字。
Models in pycorrector
- kenlm:kenlm统计语言模型工具
- rnn_attention模型:参考Stanford University的nlc模型,该模型是参加2014英文文本纠错比赛并取得第一名的方法
- rnn_crf模型:参考阿里巴巴2016参赛中文语法纠错比赛CGED2018并取得第一名的方法
- seq2seq_attention模型:在seq2seq模型加上attention机制,对于长文本效果更好,模型更容易收敛,但容易过拟合
- transformer模型:全attention的结构代替了lstm用于解决sequence to sequence问题,语义特征提取效果更好
- bert模型:中文fine-tuned模型,使用MASK特征纠正错字
- conv_seq2seq模型:基于Facebook出品的fairseq,北京语言大学团队改进ConvS2S模型用于中文纠错,在NLPCC-2018的中文语法纠错比赛中,是唯一使用单模型并取得第三名的成绩
Detector in pycorrector
- 字粒度:语言模型困惑度(ppl)检测某字的似然概率值低于句子文本平均值,则判定该字是疑似错别字的概率大
- 词粒度:切词后不在词典中的词是疑似错词的概率大
Corrector in pycorrector
- 通过错误检测定位所有疑似错误后,取所有疑似错字的音似、形似候选词
- 使用候选词替换,基于语言模型得到类似翻译模型的候选排序结果,得到最优纠正词
Defect in pycorrector
- 现在的处理手段,在词粒度的错误召回还不错,但错误纠正的准确率还有待提高
- 现在的文本错误不再局限于字词粒度上的拼写错误,需要提高中文语法错误检测(CGED, Chinese Grammar Error Diagnosis)及纠正能力
YoungCorrector
本项目是参考Pycorrector实现的一套基于规则的纠错系统。 总体来说,基于规则的文本纠错,性能取决于纠错词典和分词质量。目前与 Pycorrector相比,在准确率差不多的情况下,本模型所用的时间会少很多(归功于前向最大匹配替代了直接索引混淆词典)。
基于规则的中文纠错流程
文本处理
- 是否为空
- 是否全是英文
- 统一编码
- 统一文本格式
错误检索
从混淆词典/字典中检索
直接检索
最大匹配算法
分词后,查看是否存在于通用词典
分词质量
分词后产生的单字(字本身是ok的,但是在整个句子中是错误的)
分词后产生的错词(词本身是ok的,但是在整个句子中是错误的)
分词后的词是否包含其他字母及符号
词粒度的 N-gram
计算局部得分
MAD(Median Absolute Deviation)
字粒度的 N-gram
计算局部得分
MAD(Median Absolute Deviation)
将候选错误词中的连续单字合并
候选召回
编辑距离
错误词的长度大于 1
只使用编辑距离为 1
只使用变换和修改,无添加和删除
对编辑距离得到的词使用拼音加以限制
音近词
形近词
纠错排序
- 语言模型计算得分(困惑度)
参考
Chen, Wei, et al. “ASR error detection in a conversational spoken language translation system.” 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2013.
Ge, Tao, Furu Wei, and Ming Zhou. “Reaching human-level performance in automatic grammatical error correction: An empirical study.” arXiv preprint arXiv:1807.01270 (2018).
Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
Zhang, Shaohua, et al. “Spelling error correction with soft-masked BERT.” arXiv preprint arXiv:2005.07421 (2020).
Clark, Kevin, et al. “Electra: Pre-training text encoders as discriminators rather than generators.” arXiv preprint arXiv:2003.10555 (2020).



