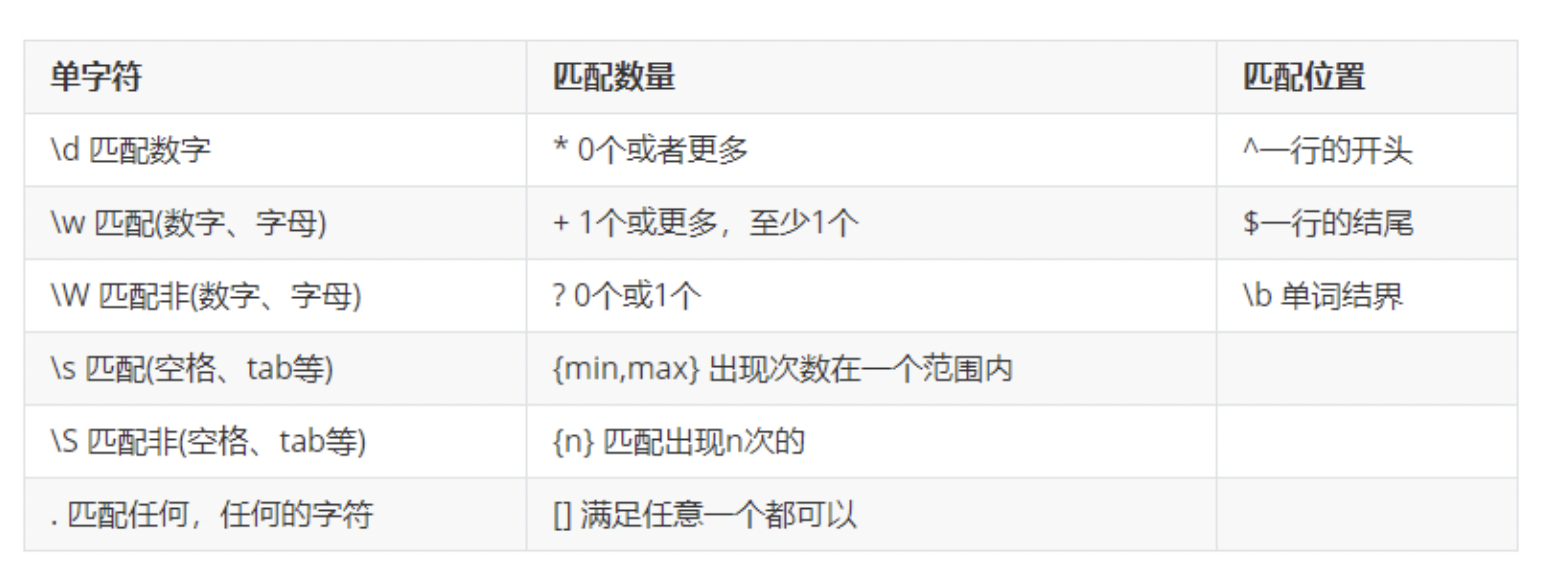
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
在线测试正则表达式网站:regex101
import re
# matching string
pattern1 = "cat"
pattern2 = "bird"
string = "dog runs to cat"
print(pattern1 in string) # True
print(pattern2 in string) # False
# regular expression
pattern1 = "cat"
pattern2 = "bird"
string = "dog runs to cat"
print(re.search(pattern1, string)) # <_sre.SRE_Match object; span=(12, 15), match='cat'>
print(re.search(pattern2, string)) # None
# multiple patterns ("run" or "ran")
ptn = r"r[au]n" # start with "r" means raw string
print(re.search(ptn, "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 7), match='run'>
# continue
print(re.search(r"r[A-Z]n", "dog runs to cat")) # None
print(re.search(r"r[a-z]n", "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 7), match='run'>
print(re.search(r"r[0-9]n", "dog r2ns to cat")) # <_sre.SRE_Match object; span=(4, 7), match='r2n'>
print(re.search(r"r[0-9a-z]n", "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 7), match='run'>
# \d : decimal digit
print(re.search(r"r\dn", "run r4n")) # <_sre.SRE_Match object; span=(4, 7), match='r4n'>
# \D : any non-decimal digit
print(re.search(r"r\Dn", "run r4n")) # <_sre.SRE_Match object; span=(0, 3), match='run'>
# \s : any white space [\t\n\r\f\v]
print(re.search(r"r\sn", "r\nn r4n")) # <_sre.SRE_Match object; span=(0, 3), match='r\nn'>
# \S : opposite to \s, any non-white space
print(re.search(r"r\Sn", "r\nn r4n")) # <_sre.SRE_Match object; span=(4, 7), match='r4n'>
# \w : [a-zA-Z0-9_]
print(re.search(r"r\wn", "r\nn r4n")) # <_sre.SRE_Match object; span=(4, 7), match='r4n'>
# \W : opposite to \w
print(re.search(r"r\Wn", "r\nn r4n")) # <_sre.SRE_Match object; span=(0, 3), match='r\nn'>
# \b : empty string (only at the start or end of the word)
print(re.search(r"\bruns\b", "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 8), match='runs'>
# \B : empty string (but not at the start or end of a word)
print(re.search(r"\B runs \B", "dog runs to cat")) # <_sre.SRE_Match object; span=(8, 14), match=' runs '>
# \\ : match \
print(re.search(r"runs\\", "runs\ to me")) # <_sre.SRE_Match object; span=(0, 5), match='runs\\'>
# . : match anything (except \n)
print(re.search(r"r.n", "r[ns to me")) # <_sre.SRE_Match object; span=(0, 3), match='r[n'>
# ^ : match line beginning
print(re.search(r"^dog", "dog runs to cat")) # <_sre.SRE_Match object; span=(0, 3), match='dog'>
# $ : match line ending
print(re.search(r"cat$", "dog runs to cat")) # <_sre.SRE_Match object; span=(12, 15), match='cat'>
# ? : may or may not occur
print(re.search(r"Mon(day)?", "Monday")) # <_sre.SRE_Match object; span=(0, 6), match='Monday'>
print(re.search(r"Mon(day)?", "Mon")) # <_sre.SRE_Match object; span=(0, 3), match='Mon'>
# multi-line
string = """
dog runs to cat.
I run to dog.
"""
print(re.search(r"^I", string)) # None
print(re.search(r"^I", string, flags=re.M)) # <_sre.SRE_Match object; span=(18, 19), match='I'>
# * : occur 0 or more times
print(re.search(r"ab*", "a")) # <_sre.SRE_Match object; span=(0, 1), match='a'>
print(re.search(r"ab*", "abbbbb")) # <_sre.SRE_Match object; span=(0, 6), match='abbbbb'>
# + : occur 1 or more times
print(re.search(r"ab+", "a")) # None
print(re.search(r"ab+", "abbbbb")) # <_sre.SRE_Match object; span=(0, 6), match='abbbbb'>
# {n, m} : occur n to m times
print(re.search(r"ab{2,10}", "a")) # None
print(re.search(r"ab{2,10}", "abbbbb")) # <_sre.SRE_Match object; span=(0, 6), match='abbbbb'>
# group
match = re.search(r"(\d+), Date: (.+)", "ID: 021523, Date: Feb/12/2017")
print(match.group()) # 021523, Date: Feb/12/2017
print(match.group(1)) # 021523
print(match.group(2)) # Date: Feb/12/2017
match = re.search(r"(?P<id>\d+), Date: (?P<date>.+)", "ID: 021523, Date: Feb/12/2017")
print(match.group('id')) # 021523
print(match.group('date')) # Date: Feb/12/2017
# findall
print(re.findall(r"r[ua]n", "run ran ren")) # ['run', 'ran']
# | : or
print(re.findall(r"(run|ran)", "run ran ren")) # ['run', 'ran']
# re.sub() replace
print(re.sub(r"r[au]ns", "catches", "dog runs to cat")) # dog catches to cat
# re.split()
print(re.split(r"[,;\.]", "a;b,c.d;e")) # ['a', 'b', 'c', 'd', 'e']
# compile
compiled_re = re.compile(r"r[ua]n")
print(compiled_re.search("dog ran to cat")) # <_sre.SRE_Match object; span=(4, 7), match='ran'>
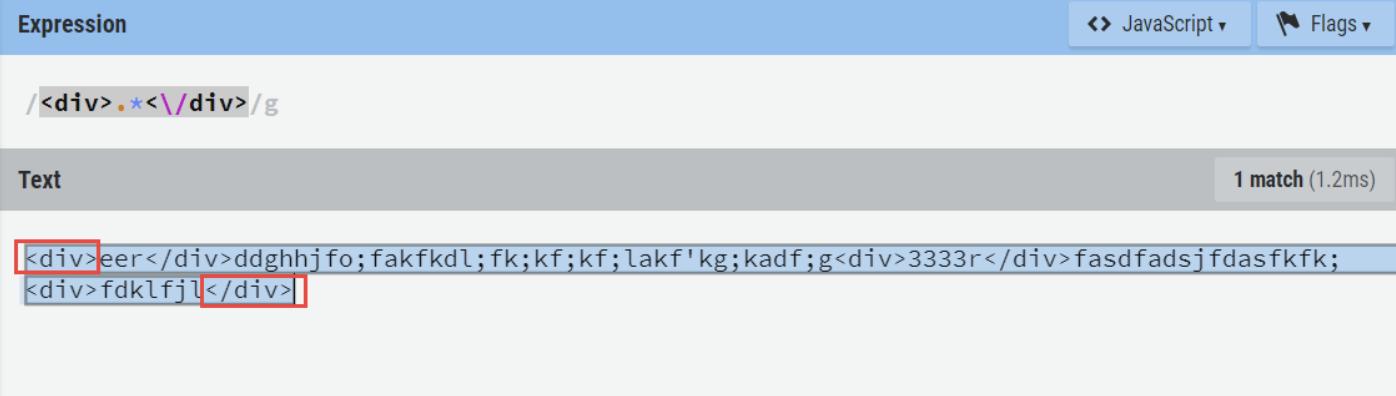
贪婪模式:会匹配最长的以开始位置开始,以结束位置结束的字符串;
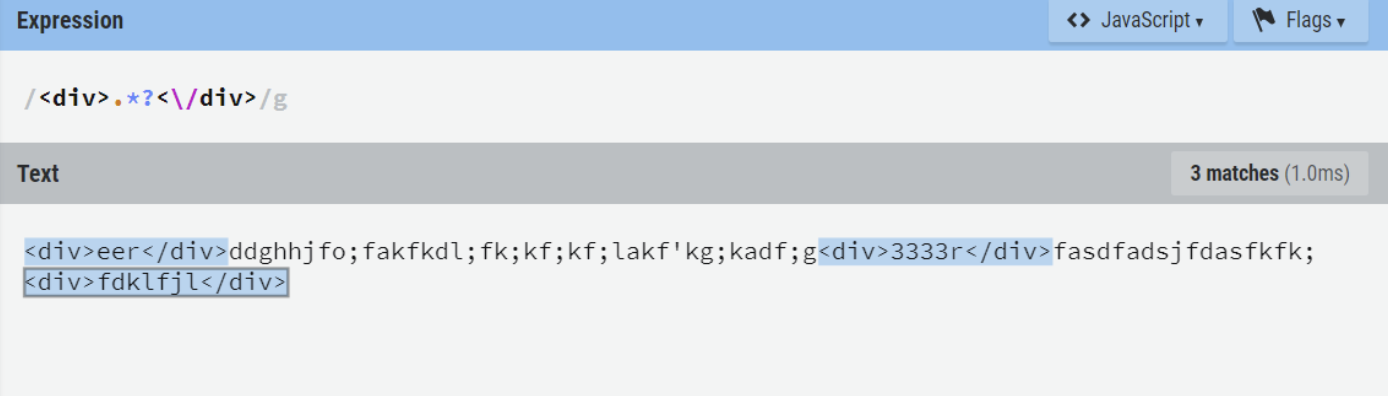
懒惰模式:匹配尽可能少的字符。