2012 年 5 月 17 日,Google 正式提出了知识图谱(Knowledge Graph)的概念,其初衷是为了优化搜索引擎返回的结果,增强用户搜索质量及体验。传统的互联网技术是基于关键字匹配,然后通过一系列的打分策略来返回搜索结果的。这种方法的一个很大的缺陷就是无法让计算机理解背后的语义,因此构建知识图谱的目的就是为了解决这一问题,比如在Google搜索引擎里输入“Who is the wife of Bill Gates?”,我们直接可以得到答案-“Melinda Gates”。这是因为系统层面上已经创建好了一个包含“Bill Gates”和“Melinda Gates”的实体以及他俩之间关系的知识库。所以,当我们执行搜索的时候,就可以通过关键词提取(”Bill Gates”, “Melinda Gates”, “wife”)以及知识库上的匹配可以直接获得最终的答案。通过知识图谱,让机器可以具备认知能力,理解这个世界。
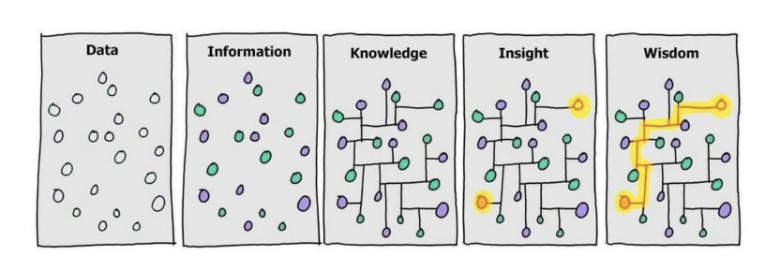
知识图谱简介
知识图谱是一种基于图的语义网络,用来展示实体间的关系。由下图可见一个知识图谱是由节点和边组成的。在知识图谱里,我们通常用“实体(Entity)”来表达图里的节点、用“关系(Relation)”来表达图里的“边”。实体指的是现实世界中的事物比如人、地名、概念、药物、公司等,关系则用来表达不同实体之间的某种联系,比如人-“居住在”-北京、张三和李四是“朋友”、逻辑回归是深度学习的“先导知识”等等。
在现实世界中,实体和关系也会拥有各自的属性,比如人可以有“姓名”和“年龄”。
知识图谱中的本体
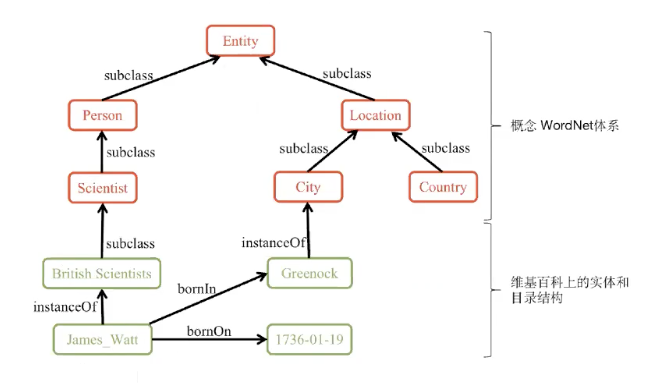
本体的概念来源自哲学,指的是对客观存在系统的解释和说明。
下面这张图就是一个本体的展示。
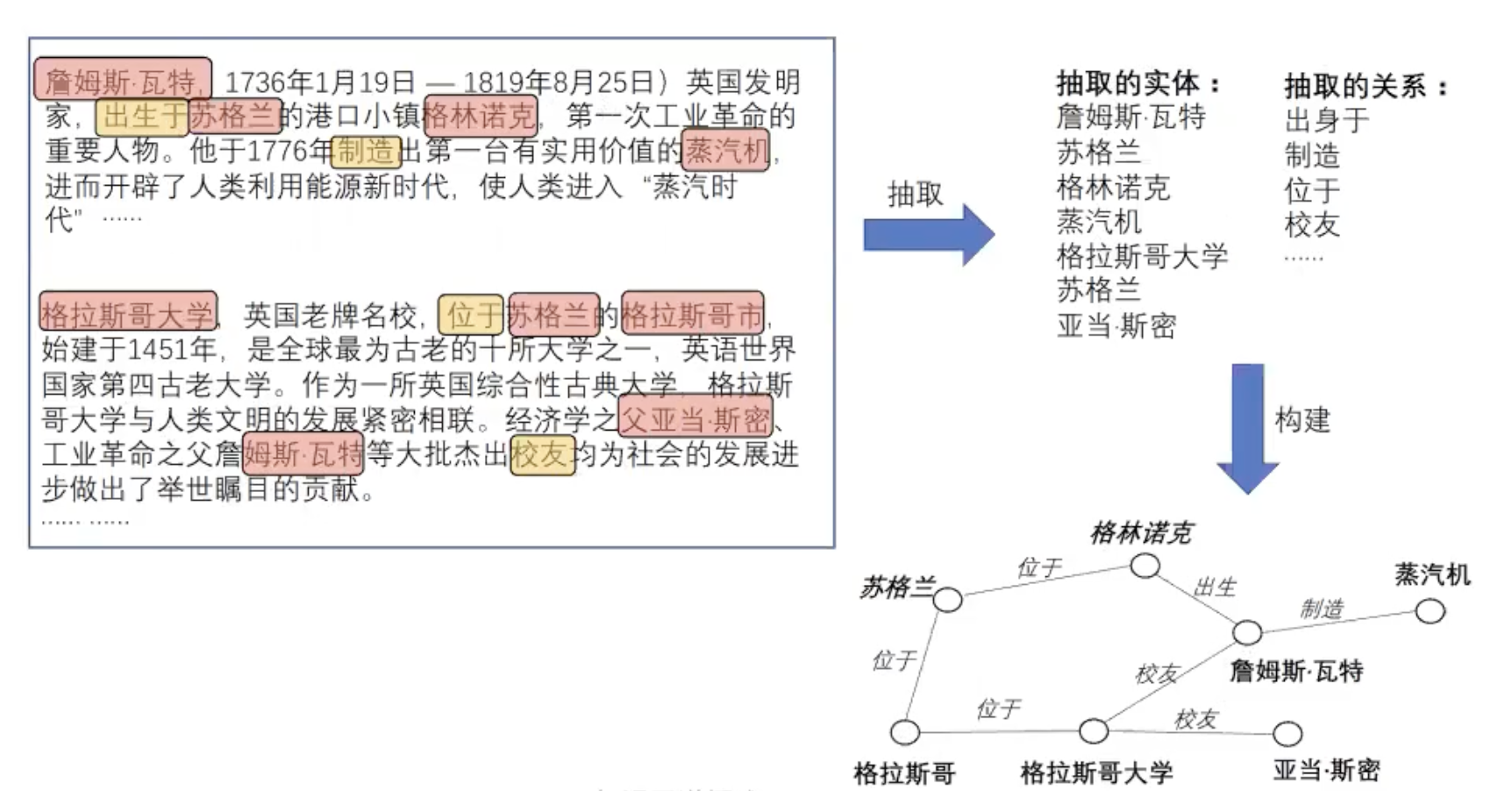
知识图谱的架构
知识图谱在架构上分,可以分为逻辑架构和技术架构。
逻辑架构
知识图谱在逻辑上可分为模式层与数据层两个层次。
- 模式层构建在数据层之上,是知识图谱的核心,通常采用本体库来管理知识图谱的模式层。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。
模式层:实体-关系-实体,实体-属性-性值
- 数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。如果用(实体1,关系,实体2)、(实体、属性,属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,例如开源的Neo4j、Twitter的FlockDB、sones的GraphDB等。
数据层:比尔盖茨-妻子-梅琳达·盖茨,比尔盖茨-总裁-微软
技术架构
知识图谱的整体架构如下图所示,其中虚线框内的部分为知识图谱的构建过程,同时也是知识图谱更新的过程。
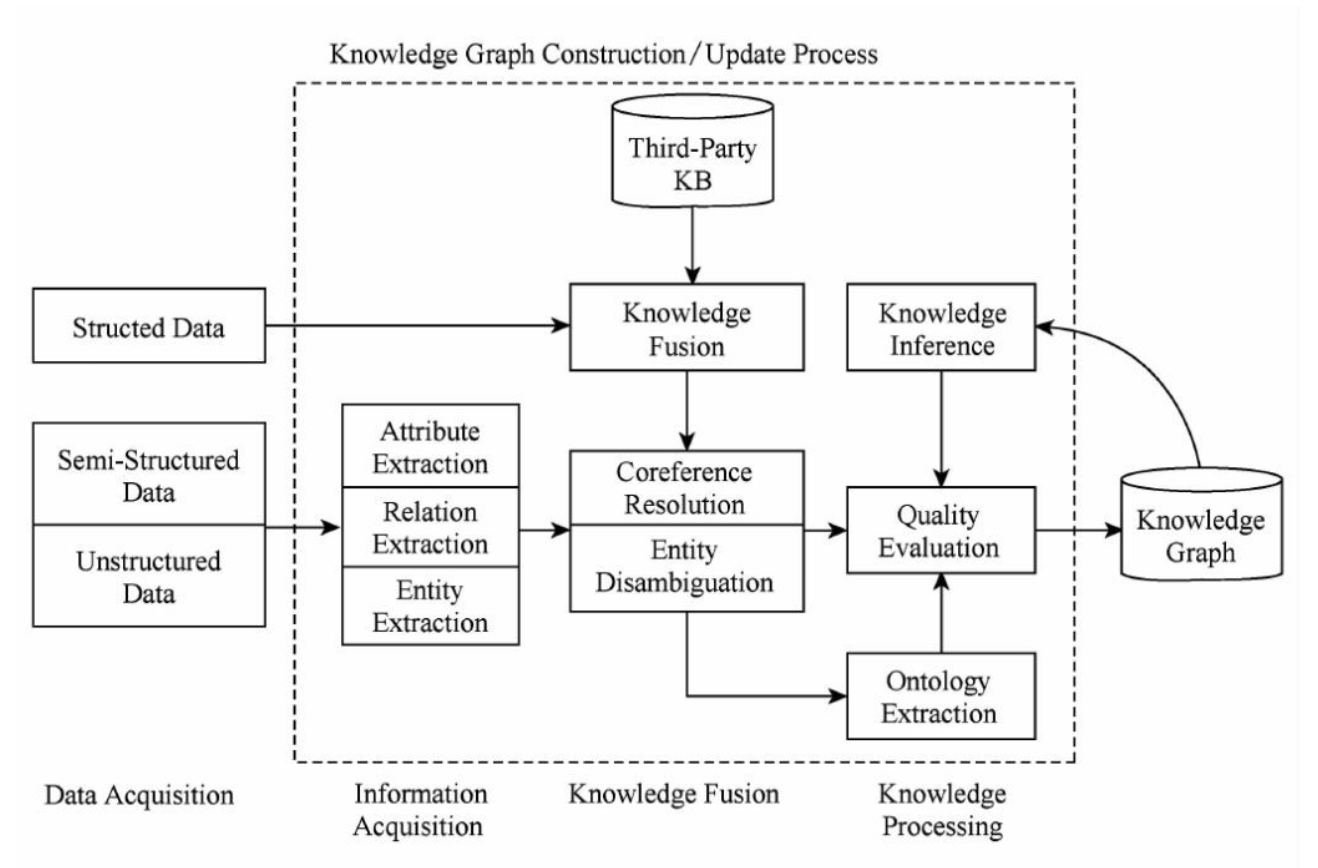
我们来一步一步的分析下这张图。
- 虚线框的最左边是三种输入数据结构,结构化数据、半结构化数据、非结构化数据。这些数据可以来自任何地方,只要它对要构建的这个知识图谱有帮助。
- 虚线框里面的是整个的知识图谱的构建过程。其中主要包含了3个阶段,信息抽取、知识融合、知识加工。
- 最右边是生成的知识图谱,而且这个技术架构是循环往复,迭代更新的过程。知识图谱不是一次性生成,是慢慢积累的过程。
- 信息抽取:从各种类型的数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化的知识表达;
- 知识融合:在获得新知识之后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应于多个不同的实体等;
- 知识加工:对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分加入到知识库中,以确保知识库的质量。
知识图谱数据模型
知识图谱的原始数据类型一般来说有三类(也是互联网上的三类原始数据):
- 结构化数据(Structed Data):如关系数据库
- 半结构化数据(Semi-Structed Data):如XML、JSON、百科
- 非结构化数据(UnStructed Data):如图片、音频、视频、文本
如何存储上面这三类数据类型呢?一般有两种选择,一个是通过RDF(资源描述框架)这样的规范存储格式来进行存储,还有一种方法,就是使用图数据库来进行存储,常用的有Neo4j等。
RDF
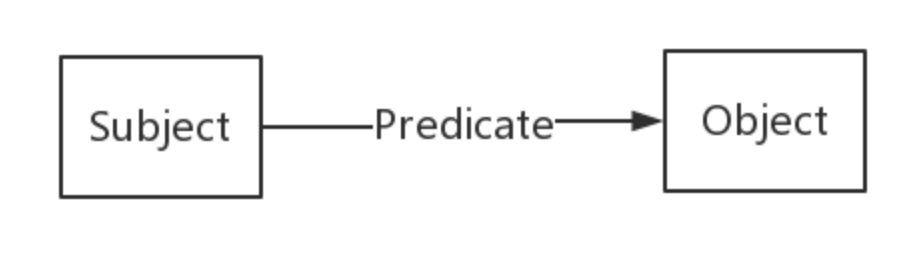
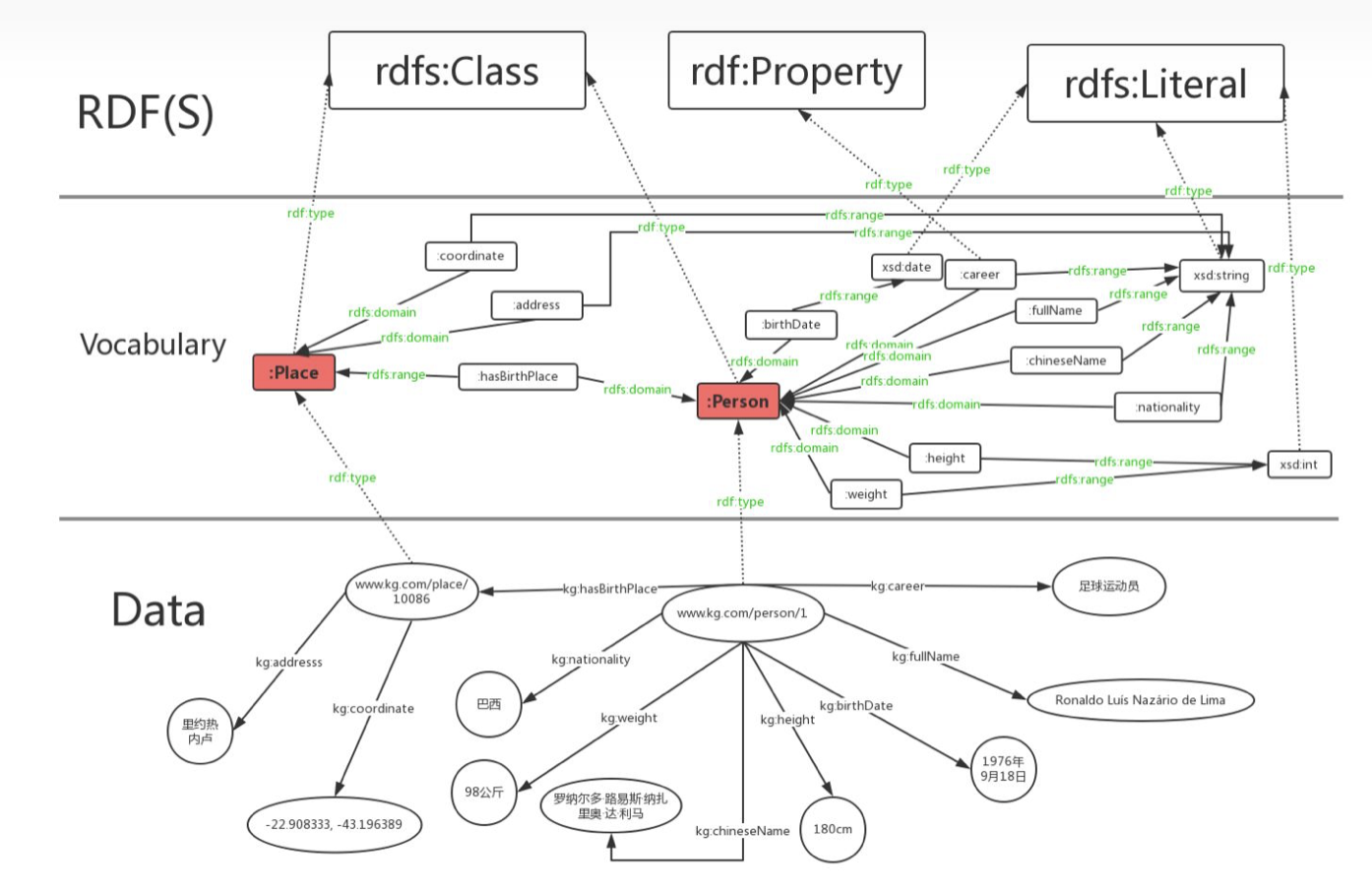
RDF(Resource Description Framework),即资源描述框架,其本质是一个数据模型(Data Model)。它提供了一个统一的标准,用于描述实体/资源。简单来说,就是表示事物的一种方法和手段。RDF形式上表示为SPO三元组,有时候也称为一条语句(statement),知识图谱中我们也称其为一条知识,如下图。
RDF在设计上的主要特点是易于发布和分享数据,但RDF的表达能力有限,无法区分类和对象,也无法定义和描述类的关系/属性。RDF是对具体事物的描述,缺乏抽象能力,无法对同一个类别的事物进行定义和描述。例如罗纳尔多和里约热内卢这两个实体,RDF能够表达罗纳尔多和里约热内卢这两个实体具有哪些属性,以及它们之间的关系。但如果我们想定义罗纳尔多是人,里约热内卢是地点,并且人具有哪些属性,地点具有哪些属性,人和地点之间存在哪些关系,这个时候RDF就表示无能为力了。不论是在智能的概念上,还是在现实的应用当中,这种泛化抽象能力都是相当重要的;同时,这也是知识图谱本身十分强调的。RDFS和OWL这两种技术或者说模式语言/本体语言(schema/ontology language)解决了RDF表达能力有限的困境。
RDFS
RDFS,即“Resource Description Framework Schema”。是在RDF数据层基础上引入模式层,定义类,属性,关系,属性的定义域与值域来描述与约束资源。
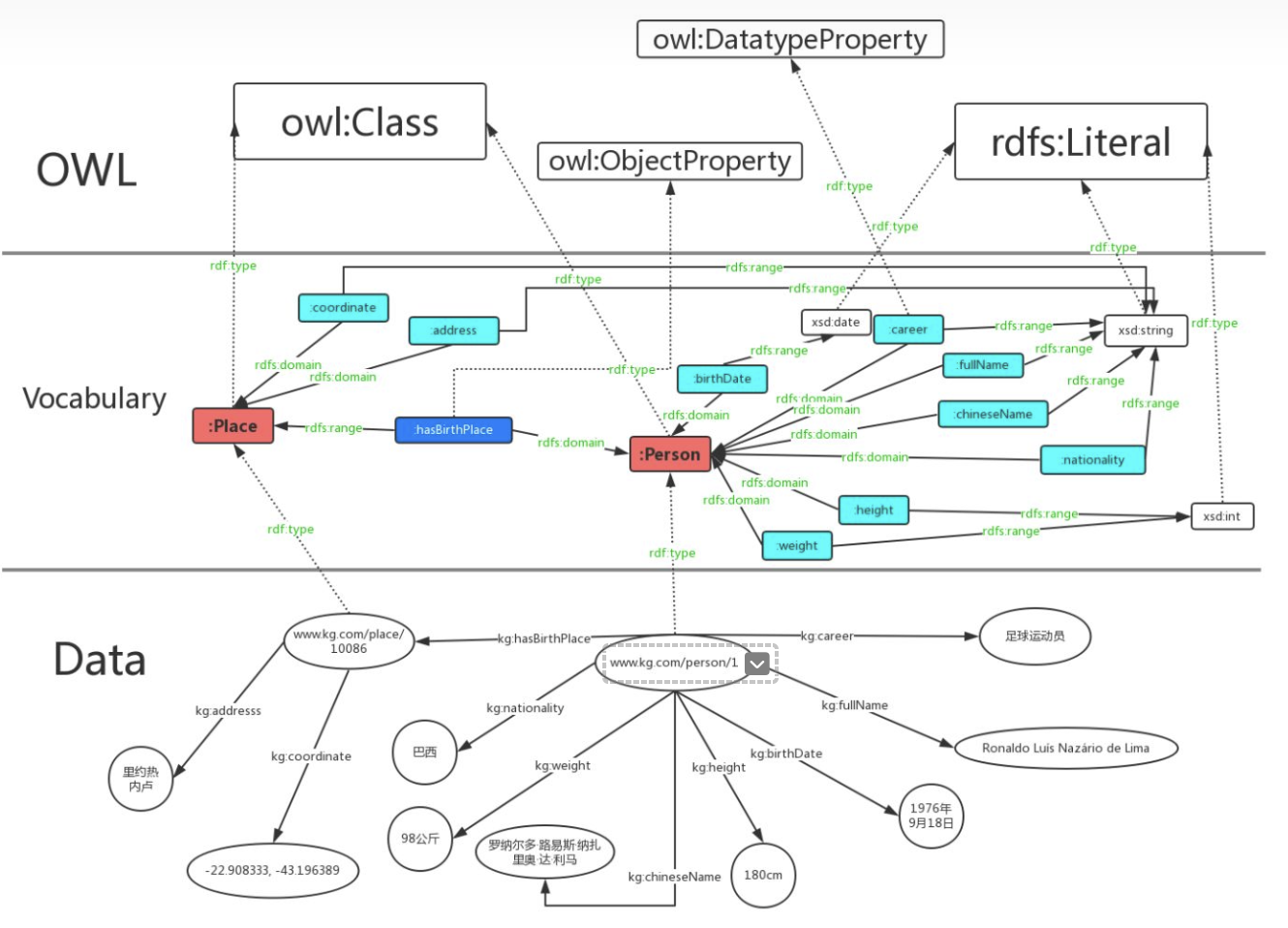
OWL
上面提到,RDFS本质上是RDF词汇的一个扩展。后来人们发现RDFS的表达能力还是相当有限,因此提出了OWL。我们也可以把OWL当做是RDFS的一个扩展,其添加了额外的预定义词汇。
OWL,即“Web Ontology Language”,语义网技术栈的核心之一。OWL有两个主要的功能:
提供快速、灵活的数据建模能力。
高效的自动推理。
描述属性特征的词汇
owl:TransitiveProperty. 表示该属性具有传递性质。例如,我们定义“位于”是具有传递性的属性,若A位于B,B位于C,那么A肯定位于C。
owl:SymmetricProperty. 表示该属性具有对称性。例如,我们定义“认识”是具有对称性的属性,若A认识B,那么B肯定认识A。
owl:FunctionalProperty. 表示该属性取值的唯一性。 例如,我们定义“母亲”是具有唯一性的属性,若A的母亲是B,在其他地方我们得知A的母亲是C,那么B和C指的是同一个人。
owl:inverseOf. 定义某个属性的相反关系。例如,定义“父母”的相反关系是“子女”,若A是B的父母,那么B肯定是A的子女。
本体映射词汇(Ontology Mapping)
owl:equivalentClass. 表示某个类和另一个类是相同的。
owl:equivalentProperty. 表示某个属性和另一个属性是相同的。
owl:sameAs. 表示两个实体是同一个实体。



