BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为Decoder是不能获要预测的信息的。
模型的主要创新点都在pre-train方法上,即用了Masked LM(MLM)和Next Sentence Prediction(NSP)两种方法分别捕捉词语和句子级别的representation。
模型结构
BERT的网络架构使用的是《Attention is all you need》中提出的多层Transformer结构,其最大的特点是抛弃了传统的RNN和CNN,通过Attention机制将任意位置的两个单词的距离转换成1,有效的解决了NLP中棘手的长期依赖问题。
Transformer的结构在NLP领域中已经得到了广泛应用,并且作者已经发布在TensorFlow的tensor2tensor库中。
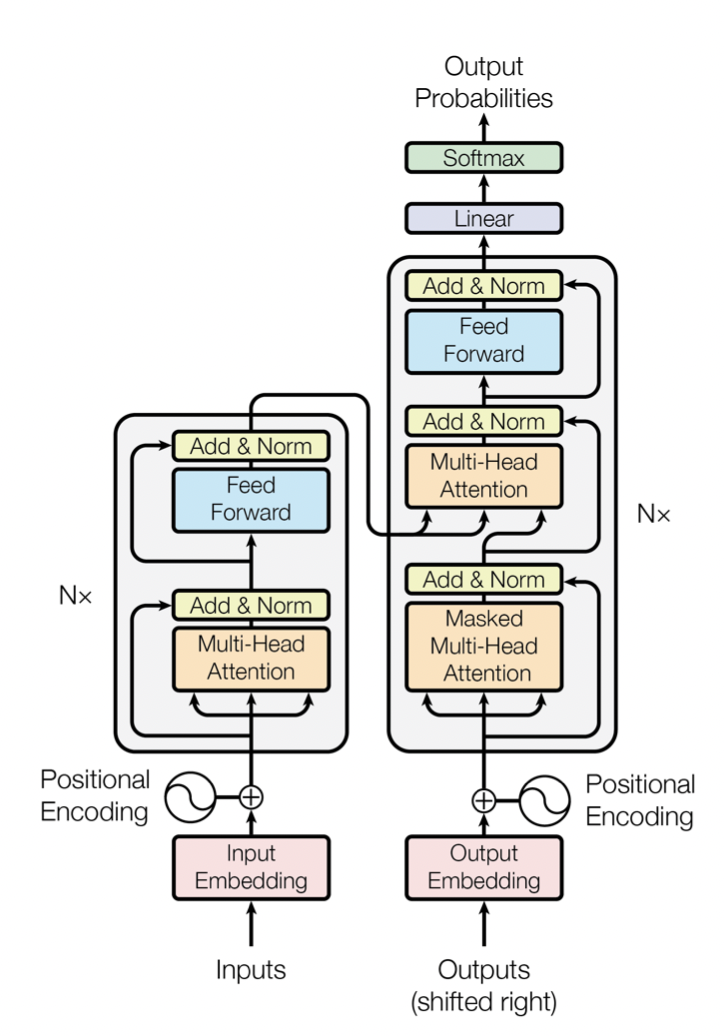
Transformer的网络架构下图所示,Transformer是一个encoder-decoder的结构,由若干个编码器和解码器堆叠形成。
左侧部分为编码器,由Multi-Head Attention和一个全连接组成,用于将输入语料转化成特征向量。
右侧部分是解码器,其输入为编码器的输出以及已经预测的结果,由Masked Multi-Head Attention, Multi-Head Attention以及一个全连接组成,用于输出最后结果的条件概率。
Self- Attention与传统的Attention机制非常的不同:传统的Attention是基于source端和target端的隐变量(hidden state)计算Attention的,得到的结果是源端(source端)的每个词与目标端(target端)每个词之间的依赖关系。
但Self -Attention不同,它首先分别在source端和target端进行自身的attention,仅与source input或者target input自身相关的Self -Attention,以捕捉source端或target端自身的词与词之间的依赖关系;然后再把source端的得到的self -Attention加入到target端得到的Attention中,称作为Cross-Attention,以捕捉source端和target端词与词之间的依赖关系。
因此,Self -Attention比传统的Attention mechanism效果要好,主要原因之一是,传统的Attention机制忽略了源端或目标端句子中词与词之间的依赖关系,相对比,self Attention可以不仅可以得到源端与目标端词与词之间的依赖关系,同时还可以有效获取源端或目标端自身词与词之间的依赖关系。
当隐藏了Transformer的详细结构后,我们就可以用一个只有输入和输出的黑盒子来表示它了,而Transformer又可以进行堆叠,形成一个更深的神经网络:
huggingface库:
128维度:uer/chinese_roberta_L-2_H-128
768维度:hfl/chinese-macbert-base
Bert 源码解析
本文基于Transformers版本4.4.2(2021年3月19日发布)项目中,pytorch版的BERT相关代码。
Tokenization(BertTokenizer)
和BERT有关的Tokenizer主要写在/models/bert/tokenization_bert.py和/models/bert/tokenization_bert_fast.py 中。
这两份代码分别对应基本的BertTokenizer,以及不进行token到index映射的BertTokenizerFast,这里主要讲解第一个。
class BertTokenizer(PreTrainedTokenizer):
"""
Construct a BERT tokenizer. Based on WordPiece.
This tokenizer inherits from :class:`~transformers.PreTrainedTokenizer` which contains most of the main methods.
Users should refer to this superclass for more information regarding those methods.
...
"""BertTokenizer 是基于BasicTokenizer和WordPieceTokenizer 的分词器:
BasicTokenizer负责处理的第一步——按标点、空格等分割句子,并处理是否统一小写,以及清理非法字符。
- 对于中文字符,通过预处理(加空格)来按字分割;
- 同时可以通过
never_split指定对某些词不进行分割;这一步是可选的(默认执行)。
WordPieceTokenizer在词的基础上,进一步将词分解为子词(subword) 。
- subword介于char和word之间,既在一定程度保留了词的含义,又能够照顾到英文中单复数、时态导致的词表爆炸和未登录词的OOV(Out-Of-Vocabulary)问题,将词根与时态词缀等分割出来,从而减小词表,也降低了训练难度;
- 例如,tokenizer这个词就可以拆解为“token”和“##izer”两部分,注意后面一个词的“##”表示接在前一个词后面。
BertTokenizer 有以下常用方法:
from_pretrained:从包含词表文件(vocab.txt)的目录中初始化一个分词器;tokenize:将文本(词或者句子)分解为子词列表;convert_tokens_to_ids:将子词列表转化为子词对应下标的列表;convert_ids_to_tokens:与上一个相反;convert_tokens_to_string:将subword列表按“##”拼接回词或者句子;encode:对于单个句子输入,分解词并加入特殊词形成“[CLS], x, [SEP]”的结构并转换为词表对应下标的列表;对于两个句子输入(多个句子只取前两个),分解词并加入特殊词形成“[CLS], x1, [SEP], x2, [SEP]”的结构并转换为下标列表;decode:可以将encode方法的输出变为完整句子。
以及,类自身的方法:
>>> from transformers import BertTokenizer
>>> bt = BertTokenizer.from_pretrained('./bert-base-uncased/')
>>> bt('I like natural language progressing!')
{'input_ids': [101, 1045, 2066, 3019, 2653, 27673, 999, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}Model(BertModel)
和BERT模型有关的代码主要写在/models/bert/modeling_bert.py中,这一份代码有一千多行,包含BERT模型的基本结构和基于它的微调模型等。
下面从BERT模型本体入手分析:
class BertModel(BertPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in `Attention is
all you need <https://arxiv.org/abs/1706.03762>`__ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the :obj:`is_decoder` argument of the configuration
set to :obj:`True`. To be used in a Seq2Seq model, the model needs to initialized with both :obj:`is_decoder`
argument and :obj:`add_cross_attention` set to :obj:`True`; an :obj:`encoder_hidden_states` is then expected as an
input to the forward pass.
""" BertModel主要为transformer encoder结构,包含三个部分:
embeddings,即BertEmbeddings类的实体,对应词嵌入;encoder,即BertEncoder类的实体;pooler, 即BertPooler类的实体,这一部分是可选的。(BertPooler模块本质上就是一个全连接层网络),使BertPooler模块的全连接层只接收BertEncoder模块中第一个token([CLS])对应的输出,因为BertPooler模块用于解决序列级任务,而序列级任务只会用到[CLS]位置对应的输出。
补充:注意BertModel也可以配置为Decoder,不过下文中不包含对这一部分的讨论。
下面将介绍BertModel的前向传播过程中各个参数的含义以及返回值:
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
): ...input_ids:经过tokenizer分词后的subword对应的下标列表;attention_mask:在self-attention过程中,这一块mask用于标记subword所处句子和padding的区别,将padding部分填充为0;token_type_ids: 标记subword当前所处句子(第一句/第二句/padding);position_ids: 标记当前词所在句子的位置下标;head_mask: 用于将某些层的某些注意力计算无效化;inputs_embeds: 如果提供了,那就不需要input_ids,跨过embedding lookup过程直接作为Embedding进入Encoder计算;encoder_hidden_states: 这一部分在BertModel配置为decoder时起作用,将执行cross-attention而不是self-attention;encoder_attention_mask: 同上,在cross-attention中用于标记encoder端输入的padding;past_key_values:这个参数貌似是把预先计算好的K-V乘积传入,以降低cross-attention的开销(因为原本这部分是重复计算);use_cache: 将保存上一个参数并传回,加速decoding;output_attentions:是否返回中间每层的attention输出;output_hidden_states:是否返回中间每层的输出;return_dict:是否按键值对的形式(ModelOutput类,也可以当作tuple用)返回输出,默认为真。
补充:注意,这里的head_mask对注意力计算的无效化,和下文提到的注意力头剪枝不同,而仅仅把某些注意力的计算结果给乘以这一系数。
返回部分如下:
# BertModel的前向传播返回部分
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)可以看出,返回值不但包含了encoder和pooler的输出,也包含了其他指定输出的部分(hidden_states和attention等,这一部分在encoder_outputs[1:])方便取用:
# BertEncoder的前向传播返回部分,即上面的encoder_outputs
if not return_dict:
return tuple(
v for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)此外,BertModel还有以下的方法,方便BERT玩家进行各种操作:
get_input_embeddings:提取embedding中的word_embeddings即词向量部分;set_input_embeddings:为embedding中的word_embeddings赋值;_prune_heads:提供了将注意力头剪枝的函数,输入为{layer_num: list of heads to prune in this layer}的字典,可以将指定层的某些注意力头剪枝。
补充:剪枝是一个复杂的操作,需要将保留的注意力头部分的Wq、Kq、Vq和拼接后全连接部分的权重拷贝到一个新的较小的权重矩阵(注意先禁止grad再拷贝),并实时记录被剪掉的头以防下标出错。具体参考
BertAttention部分的prune_heads方法。
参考
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding



